paper-reading03.md

Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
对一些传统认识的挑战
- 超大卷积不但不涨点,还会掉点?
在现代CNNC设计加持下,kernel size越大越涨点
- 超大卷积效率很差?
超大depth-wise卷积并不会增加多少FLOPs。如果再加点底层优化,速度会更快,31x31的计算密度最高可达3x3的70倍
- imagenet点数很重要?
下游任务的性能可能和imagenet关系不大
- 大卷积只能用在大feature map上?
在7x7的feature map上用13x13的卷积都能涨点
- 超深CNN堆叠大量3x3,所以感受野很大?
深层小kernel的有效感受野其实很小,反而少量超大的卷积核的有效感受野非常大
- self-attention在下游任务中性能很好是因为self-attention本质更强?
kernel size可能才是下游任务涨点的关键
提出在线代CNN中应用超大卷积核的五条准则
- 用depth-wise超大卷积,最好再加底层优化
- 加shortcut
- 用小卷积核做重参数化
- 要看下游任务的性能,不能只看ImageNet点数高低
- 小feature map上也可以用大卷积,常规分辨率就能训大kernel模型
基于五条准则,提出一种架构RepLKNet
简单借鉴Swin Transformer的宏观架构,其中大量使用超大卷积,如27x27、31x31等。这一架构的其他部分非常简单,都是1x1卷积、Batch Norm等喜闻乐见的简单结构,不用任何attention。
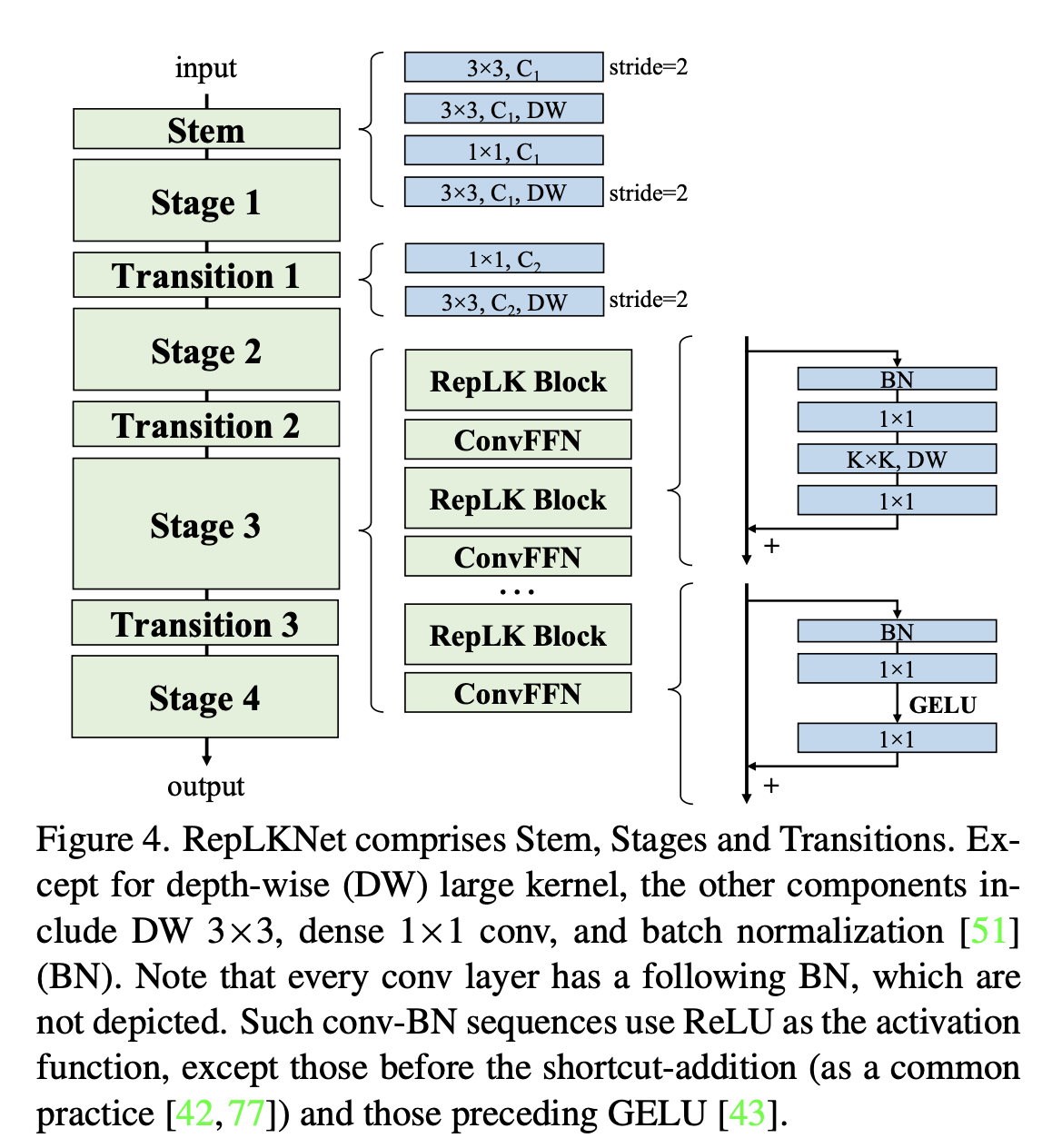
在各种下游任务上的效果
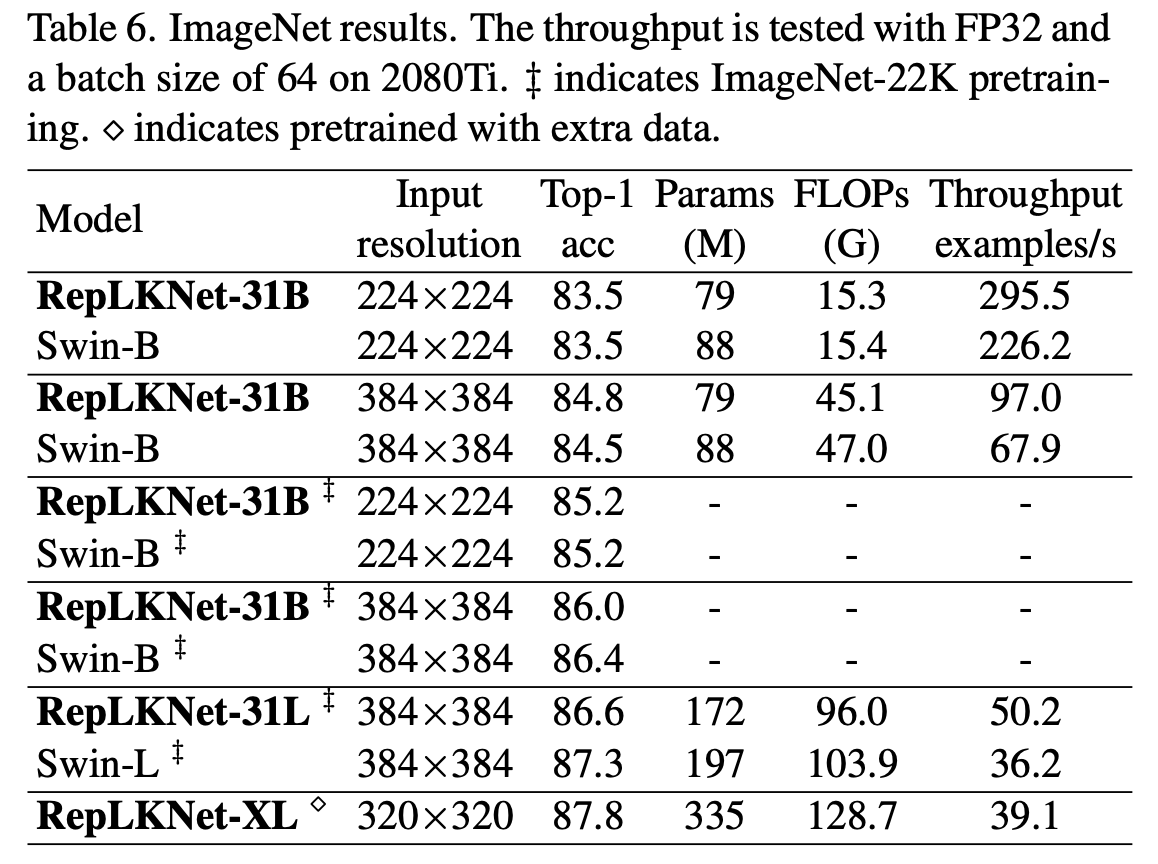
- 分类
ImageNet上,与Swin-Base相当。在额外数据训练下,超大量级模型最高达到**87.8%**的正确率。超大卷积核本来不是为刷ImageNet设计的,这个点数也算是可以让人满意。
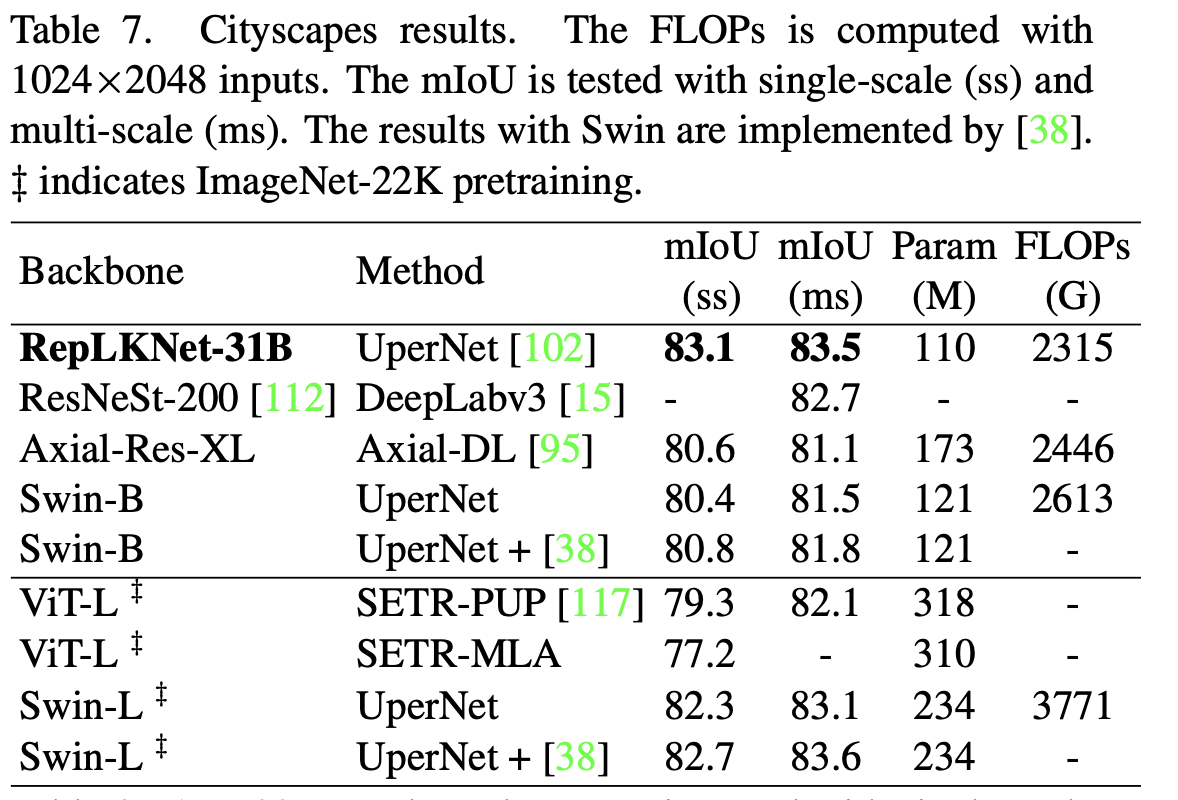
- 语义分割
Cityscapes语义分割上,仅用ImageNet-1K pretrain的RepLKNet-Base,甚至超过了ImageNet-22K pretrain的Swin-Large。这是跨模型量级、跨数据量级的超越。
ADE20K语义分割上,ImageNet-1K pretrain的模型大幅超过ResNet、ResNeSt等小kernel传统CNN。Base级别模型显著超过Swin,Large模型与Swin相当。超大量级模型达到56%的mIoU。

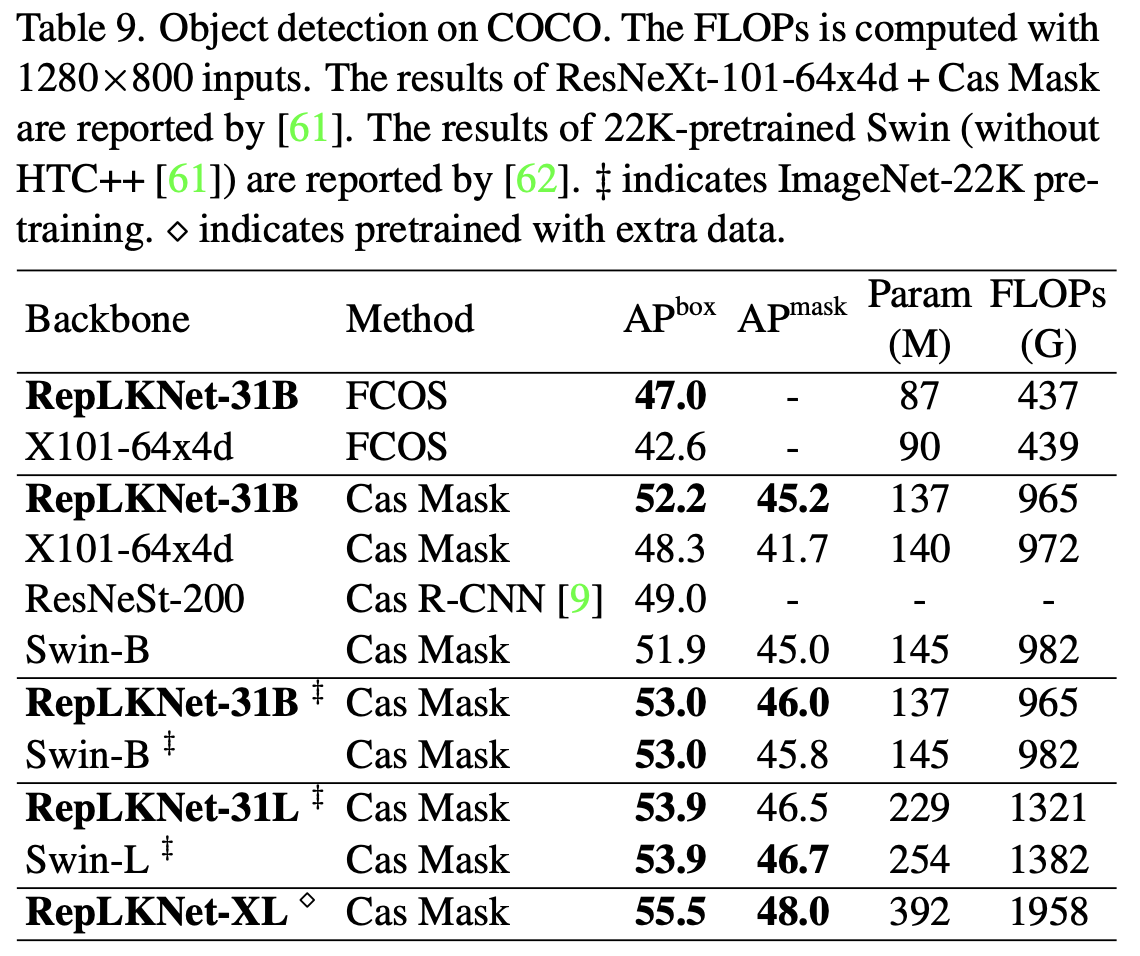
- 目标检测
COCO目标检测上,大幅超过同量级的传统模型ResNeXt-101(超了4.4的mAP),与Swin相当,在超大量级上达到55.5%的mAP。
- Post title:paper-reading03.md
- Post author:calcium_oxide
- Create time:2022-12-11 14:33:51
- Post link:https://yhg1010.github.io/2022/12/11/paper-reading03-md/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.