
weak-shot learning
zero-shot learning
definition
zero-shot learning requires category-level semantic representation word vector or human annotated attributes for all categories
requirements
both base categories and novel categories need category-level semantic representations
few-shot learning
definition
few-shot learning requires a few clean examples for new categories
types
- 基于优化的方法:在大量的学习任务上优化分类器然后可以用少量的新类别图片学习新的学习任务
- 基于内存的方法:探索内存架构来存储关键的训练数据或者直接编码快速适应的算法
- 基于尺度的方法:用一个相似度度量来学习特征空间中的一个深层表示,然后用最近邻方式来分类测试图片
comparison between zero-shot/few-shot/weak-shot learning

weakly supervised learning
- 弱监督学习和半监督学习的区别?
弱监督学习:bridge the gap between weak annotations and full annotations
半监督学习:impose prior regularzation on weakly-annoted data or transfer knowledge from fully-annotated data to weakly-annotated data
弱监督学习涉及到跨类别的知识迁移,而半监督学习并没有
weak-shot learning
tyepes
弱监督学习中将基础种类的信息迁移到新种类中来弥补新种类中的弱标注和全标注之间的间隙,大概的方法有三种:
- 迁移从基础类别到新类别的种类-不变性目标
- 迁移从弱标注到全标注的映射关系
- 将整个任务进行分解,分解成一个弱监督子任务和全监督子任务
methods
- 迁移种类-不变性目标
- 相似度:语义相似度可以表明两个实例是否属于同一个类别,从基础类别学习到的相似度预测器可以应用到新的类别上来预测成对的相似度,进而可以用来对训练样本降噪以及对新类别的特征学习进行正则
- objectness:从基础类别学到的objectness可以应用在新类别上来定位category-agnostic目标
- 边界:从基础类别中学习到的边界预测器可以用来预测新类别的语义边界,获得的边界可以用来分辨新类别的不确定的像素点或者分割目标
- saliency:可以从基础类别向新类别迁移实例显著性来帮助分割新类别的目标
- Shape:基础类别的目标形状可以作为一个形状先验的字典来帮助推理新类别的实例mask
- 迁移从弱标注到全标注的映射关系
- 标注迁移:首先从弱标注中学习到semantic masks,然后学习从粗略的semantic masks到全标注的特征图之间的映射关系
- 权重映射:学习基于弱标注的模型权重到基于全标注的模型权重之间的映射关系
- 任务分解
定义:
将整个任务分解成一个弱监督子任务和一个全监督子任务,弱监督子任务由基础类别和新类别的标注进行监督,而全监督子任务由基础类别的全监督进行监督,另外在全监督子任务中学到的知识可以跨类别进行迁移
应用
弱样本语义分割:
RETAB,两种种类不变性类别信息:semantic affinities,semantic boundries从基础类别迁移到新类别
RETAB包括一个affinity学习步骤以及一个基于affinity的传播步骤,在affinity学习步骤,主要是从基础类别的gt学习到semantic affinities以及新类别样本的CAMs
在传播步骤中,一个新型两阶段传播策略被用来传播和修正CAMs通过利用semantic affinities和semantic boundries信息
semantic segmentation
- Zero-shot learning
[5, 21, 62]
- Few-shot learning
[16, 67, 13, 25, 59]
- Weak-shot learning
- simformer(https://blog.csdn.net/qq_39575835/article/details/102635684)
- Maskformer
maskformer
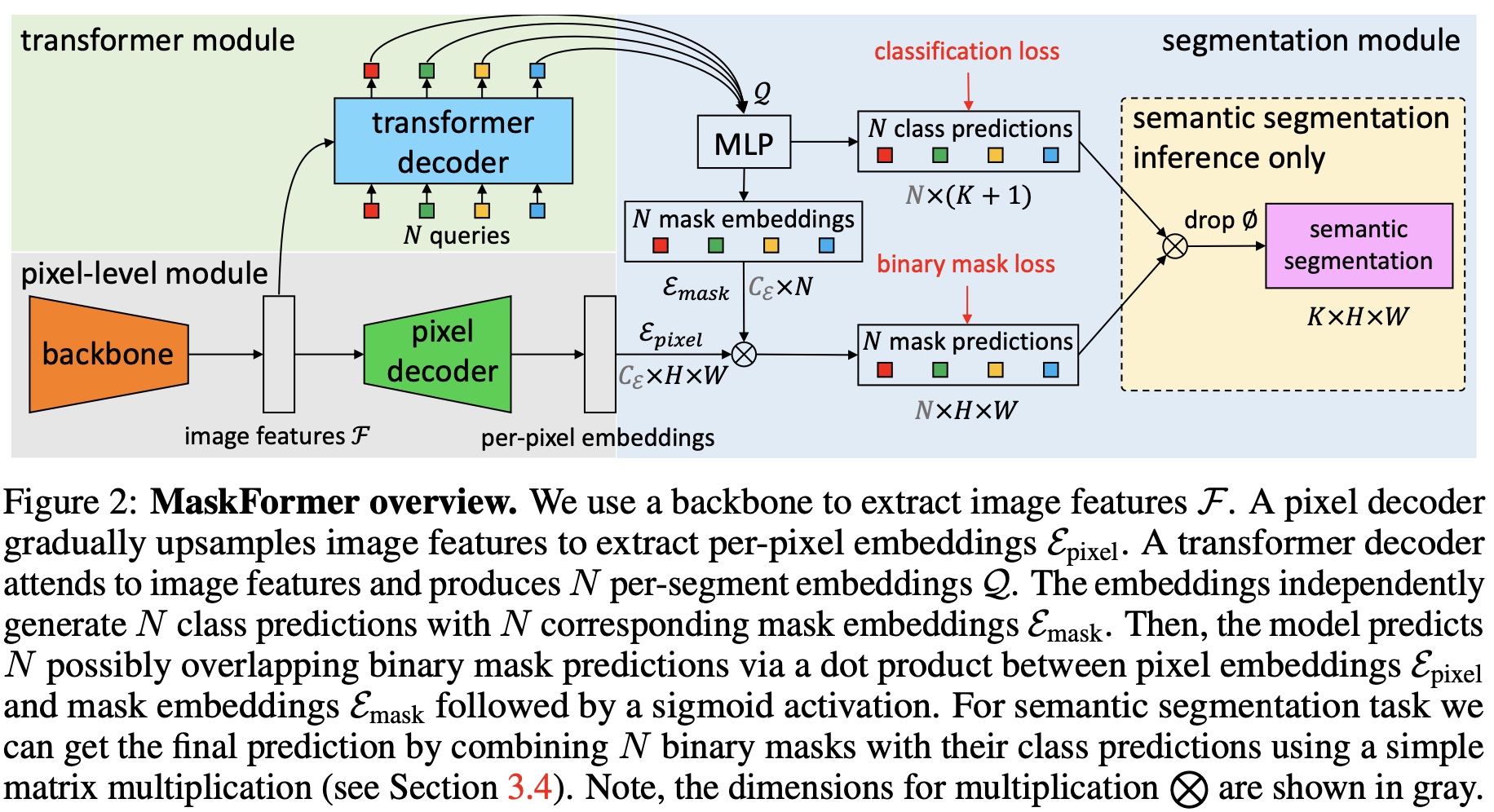
simformer
为了解决逐像素标注带来的巨大代价,将研究重点放在了弱样本语义分割任务上,借助基础类别的逐像素标注的帮助以及新类别的图片级标注学习新类别,为了解决这个问题提出了基于maskformer进行双相似度迁移的simformer,将语义分割任务分解成两个子任务:
- Proposal classification
- Proposal segmentation for each proposal
Proposal segmentation可以实现从基础类别到新类别的proposal-pixel迁移。另外,可以从基础类别学习到pixel-pixel相似度并且在新类别上的语义mask上使用这种类别无关的语义相似度。除此之外,提出了一种互补损失促进新类别的学习。
introduction
本文做出的贡献:
- 提出了一个基于maskformer的双相似度迁移框架simformer,其中maskformer本身可以实现proposal-pixel相似度迁移
- 提出了pixel-pixel相似度迁移
- 并且提出了一个互补损失
related work
- 弱监督语义分割
弱监督语义分割只依赖图片级标签来训练分割模型,大部分弱监督语义分割模型先训练一个分类器来得到类激活图(CAM)以得到伪掩膜,利用这个伪掩膜可以训练一个标准的分割模型。但由于缺乏像素级的标注,因此expanded CAM很难覆盖完整的语义区域。
- 弱样本学习
任务是借助新类别的图像级标注和基础类别的像素级标注来分割新类别。
- 相似度迁移
相似度迁移被广泛应用在各种迁移学习任务中,语义相似度是类无关的,因此可以跨类别迁移
method
- 问题定义
给定一个包含基础类别的标准分割数据集,希望能够进一步分割包含新类别的集合,拥有包含新类别的图片级标注。
maskformer
在maskformer上的proposal-pixel相似度迁移
首先通过从base classes得到的proposal-pixel相似度迁移产生novel classes的mask。
对于proposal classify任务来说,将base和novel类别的proposal embeddings作为监督:

对于segmentation子任务来说,只有base类别的mask作为监督:

在mask损失的监督下,会产生base proposal embedding和所有的pixel embedding的二值相似度关系,这种相似度关系是类无关的,可以跨类别迁移。可以计算novel类别的proposal embedding和pixel embedding来产生novel masks。
- 通过pixel simnet进行pixel-pixel相似度迁移
由于缺少novel 类别的语义监督,novel masks很难在所有训练样本中达到语义一致性,所以这里提出一种新策略来从base pixel中学习成对的语义相似度,并且在novel pixel上应用这种类别无关的语义相似度。
实现方式:
对每张输入图像,随机采样另一张图像作为其参考图像,根据图片级标注以确保这两张图像包含共同的base类别和novel类别。训练一个pixel-pixel相似度网络simnet,网络的输入是从从两张图像中各采样的J个base pixels构成的JxJ的pixel对,将配对的两个pixel embeddings进行concat得到pixel-pair embedding:$\mathbf{R^{(C+C)\times J\times J}}$,用base pixel的label作为监督,输出一个相似度score:$\mathbf{R^{J\times J}}$
得到了base pixel的相似度,如何迁移到novel pixel?
同样是从输入图像和参考图像中的not-base区域各采样J个像素点构成$\mathbf{R^{(C+C)\times J\times J}}$,使用simnet得到语义相似度$\mathbf{R^{J\times J}}$作为蒸馏源,计算novel类别的分割score,得到采样的JxJ个分割score对,从base类别到novel类别的pixel-pixel相似度迁移根据以下损失实现:

- 互补损失
尽管没有novel类别的像素级标注,但是有一个先验知识就是一张图像中的novel/ignore像素集合和base像素集合是互补的,因此可以引入这个先验损失:

- 训练和推理
整体的训练损失是:

experiment
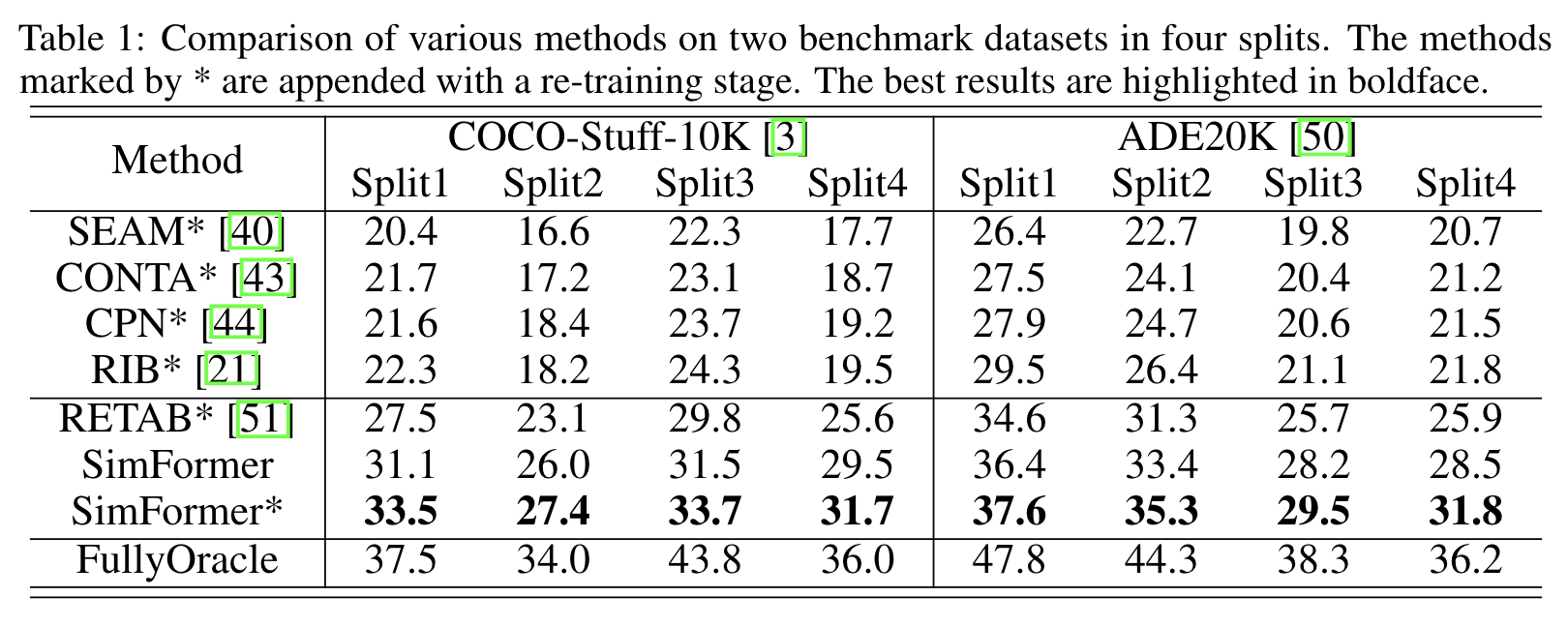
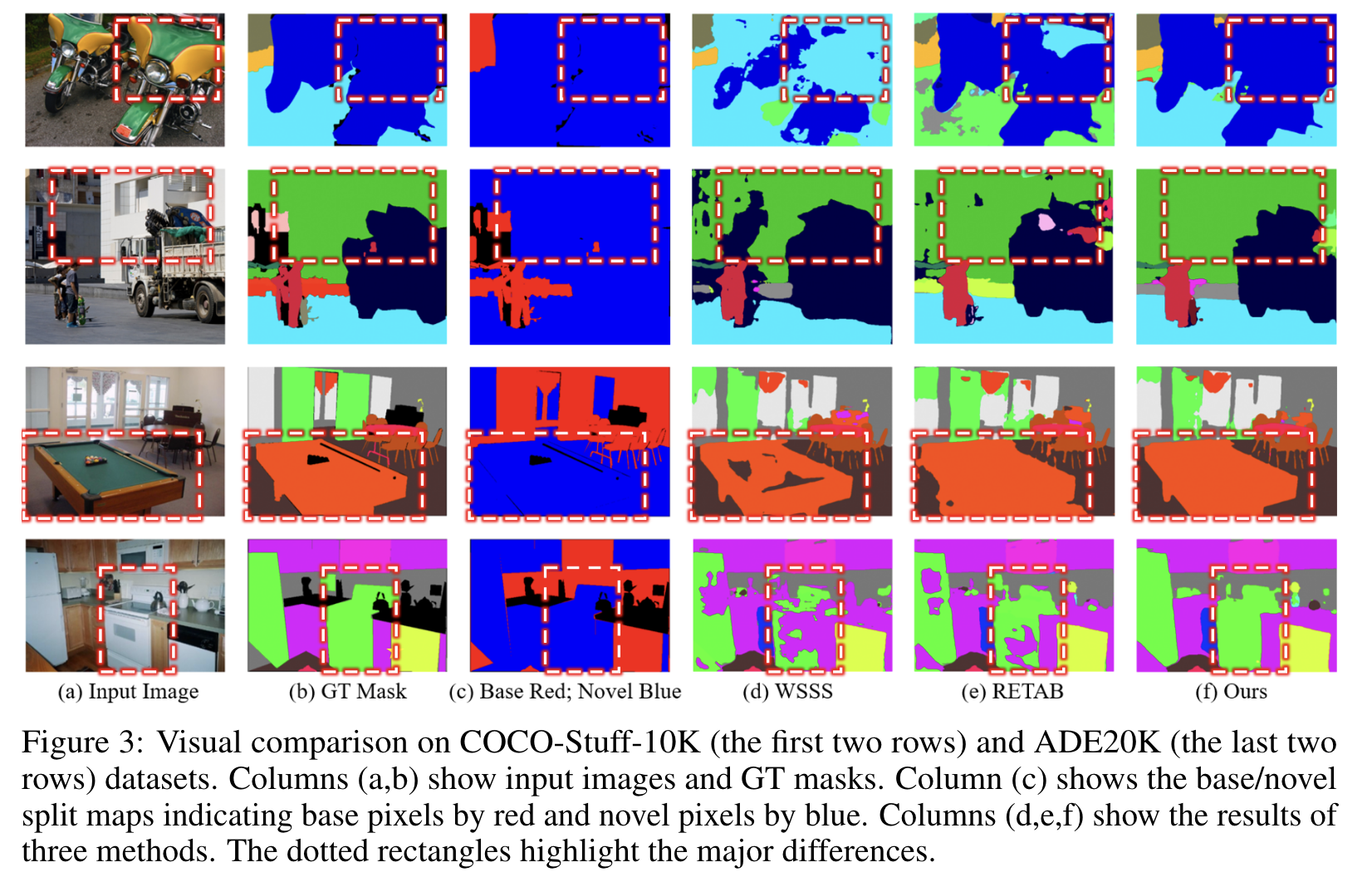
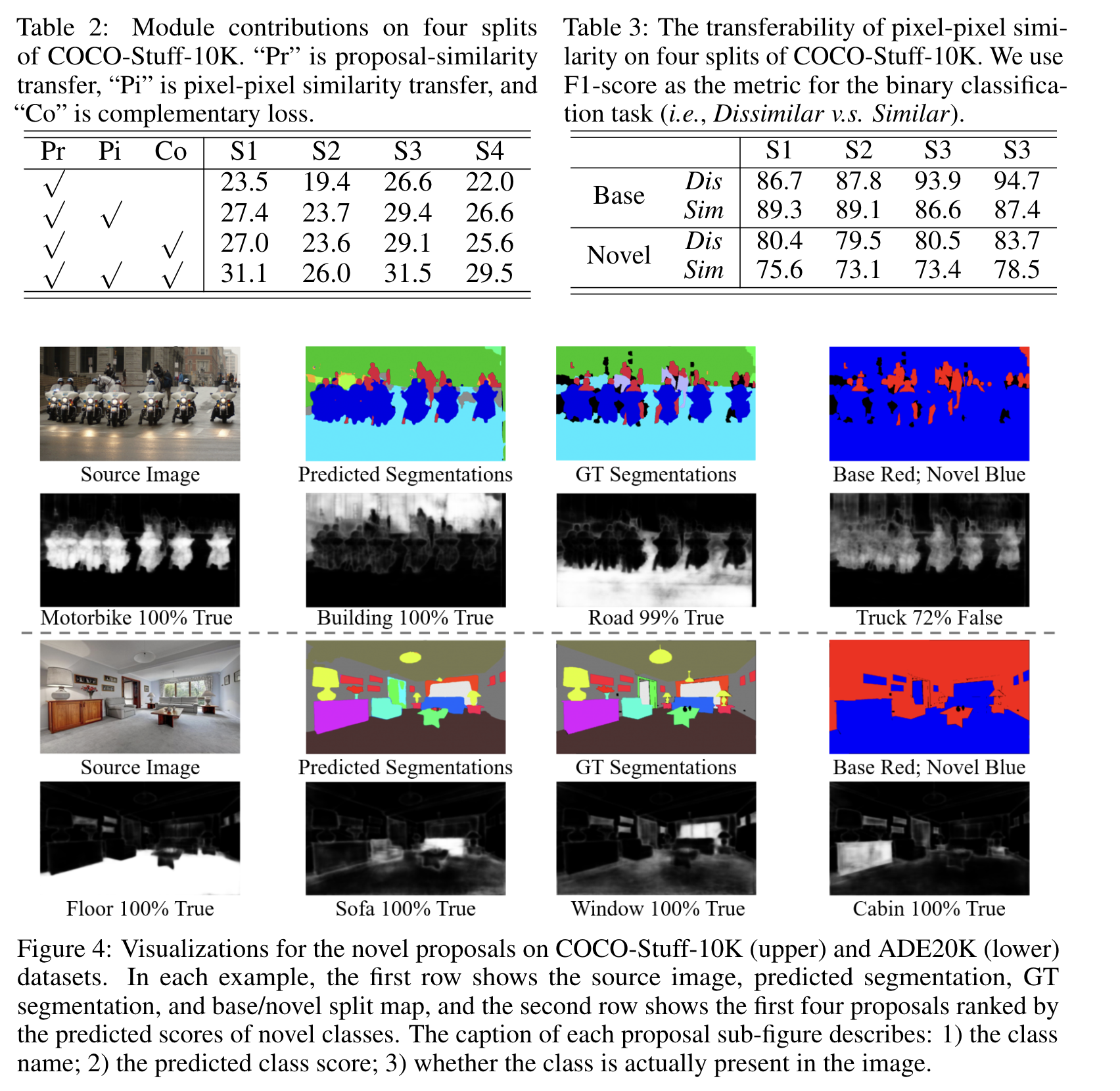

不足之处以及待改进
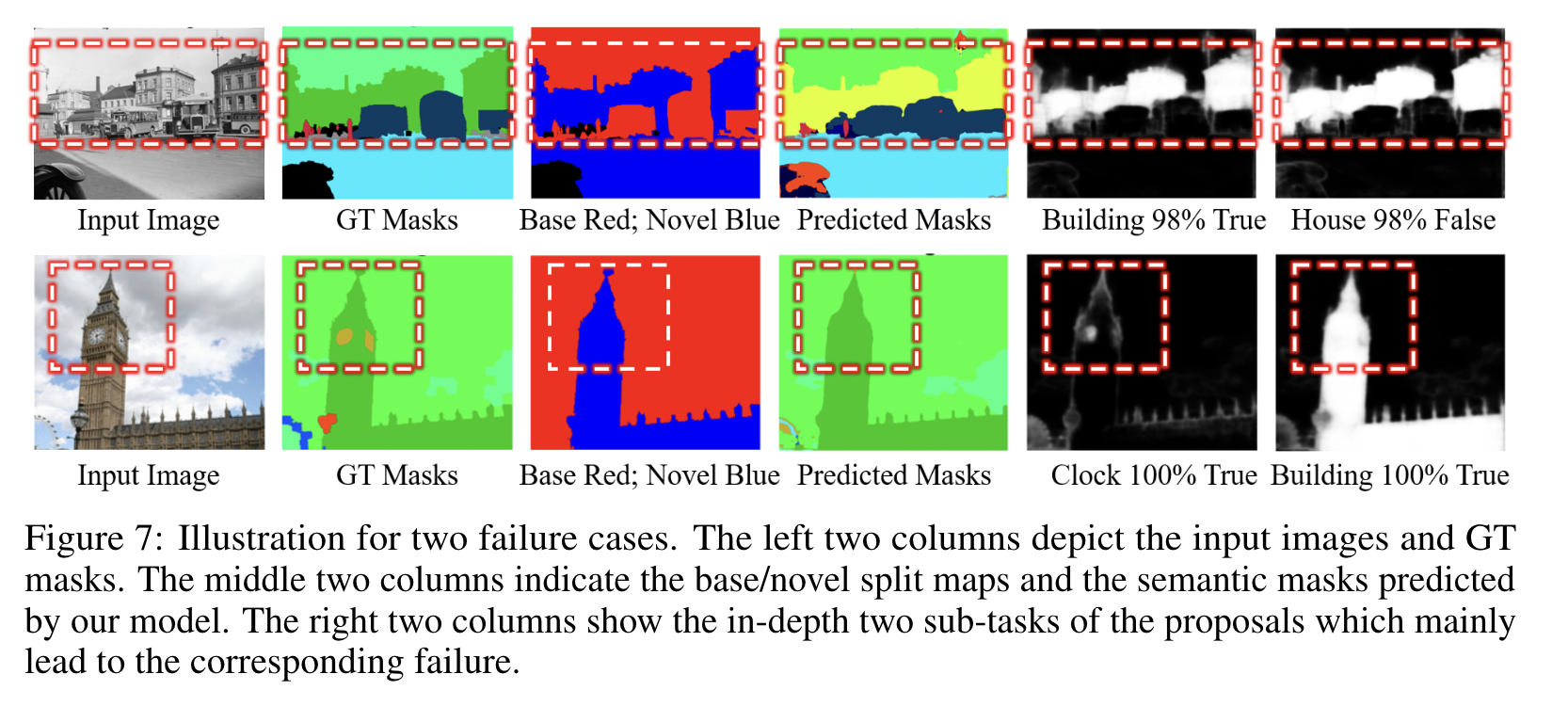
在实验过程中发现两个比较大的问题:
- 如果novel类别中存在粒度比较细的类别,proposal classify任务会出现问题,如果分类错误,就算proposal segmentation子任务做的很好,最终的分割结果也会被proposal classification子任务影响。
- Proposal segmentation子任务可能会失败,尽管两种novel类别都被成功分类,如果其中一个目标相对来说比较小,对应的二值mask相对来说也会更weak,在最终的分割结果中可能会被覆盖掉。
展望
- 可以挖掘更多跨类别的迁移目标,除了本文提出的两种相似度迁移外。
- 遥感领域的可用数据集不多,标注所花费的成本也比较大,因此将weak-shot用在遥感领域对一些难分的新类别或许有帮助。
任务辨析
- 弱监督学习
已知数据和其一一对应的弱标签,训练一个智能算法,将输入数据映射到一组更强的标签的过程。
弱监督学习可以分为三种:
- 不完全监督:部分数据有标注,部分数据没有标注
- 不确切监督:部分数据只有比较粗略的标注
- 不精确监督:部分数据的标注不精确
在额外的全标注的base category的帮助下,weak-shot学习可以视作弱监督学习(不确切监督)。
- zero-shot
zero-shot学习应用category级别语义表示弥合base category和novel category之间的差别。zero-shot学习需要base category和novel category的category级别语义表示。zero-shot学习需要提供base category和novel category的语义表示,训练集的标注是完整的,测试集包含未标注的novel category
- few-shot
few-shot需要novel category一些完全标注的样本。
weak-shot
半监督学习
半监督学习使用一组完全注释的样本和一组未注释或弱标注的样本训练采样。半监督学习通常对弱注释的样本施加先验正则化或将知识从全注释样本迁移到弱注释样本。和weak-shot学习相比,weak-shot学习涉及跨类别的知识迁移。
对比学习
知识蒸馏
弱监督语义分割
传统意义上的弱监督语义分割分成三个阶段:
- 生成类别激活图
- refine生成类别激活图
- 利用pseudo GT训练传统的语义分割网络
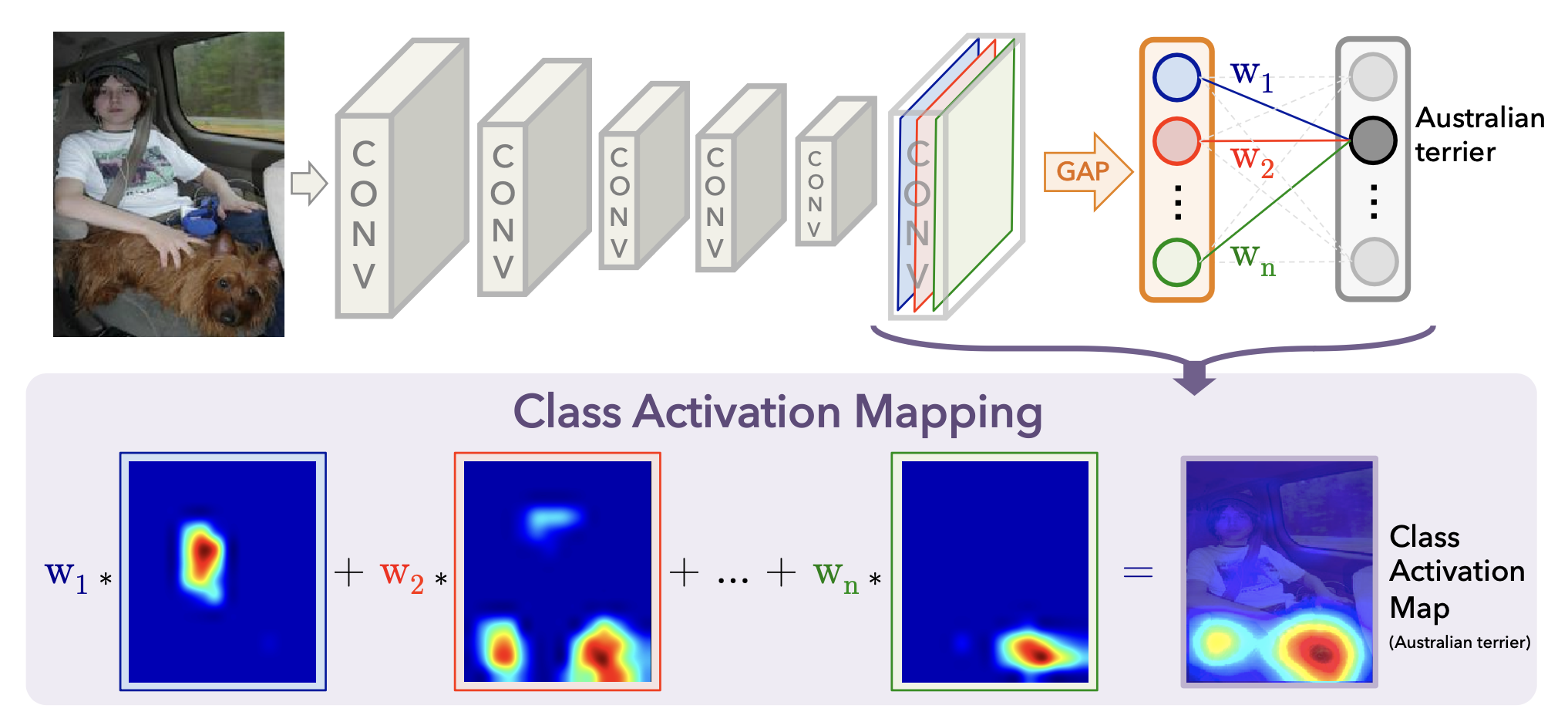
卷积神经网络里面的每一个卷积单元其实都扮演着一个个Object Detector的角色,本身就带有能够定位物体的能力。但是这种能力在利用全连接层进行分类的时候就丢失了。因此,像那些全卷积的神经网络,比如GoogLeNet,都在避免使用全连接层,转而使用Network in network中的全局平均池化层(Global Average Pooling,GAP),这样的话不仅可以减少参数,防止过拟合,还可以建立feature map到category之间的关联。
组会分享大纲
任务定义
这一部分主要就是来介绍弱样本语义分割任务的具体定义,什么是弱样本?什么是弱样本语义分割?
- 什么是弱样本?
弱样本就是包含弱标注的数据集,在不同任务中的弱样本也各不相同。
在图像分类任务中:
弱标注是具有噪声的图像级标注
在目标检测任务中:
弱标注是图像级标注
在语义分割任务中:
弱标注是图像级标注
在实例分割任务中:
弱标注是bounding boxes
- 什么是弱样本语义分割?
base category:包含逐像素标注和图像级标注的样本
novel category:只包含图像级标注的样本
弱样本语义分割就是在base category和novel category的基础上对novel category进行分割
- 弱样本语义分割的任务背景?
语义分割任务依赖图像的逐像素标注,因此为了训练语义分割模型需要大量逐像素标注,在面对新类别的语义分割任务时需要花费大量成本来进行数据集标注,因此考虑在已有的包含base类别的语义分割数据集和novel类别的弱标注的基础上对novel类别进行分割
介绍完弱样本语义分割之后,可以叉开简单对比一下弱样本和弱监督之间的区别,提一下弱监督语义分割的主流框架
再介绍一下弱样本语义分割的领域比较新,上交的牛力等人对弱样本学习的分类、检测、分割领域都做了一遍,主要工作都是由牛力等人完成
论文1 Weak-shot semantic segmentation by transferring semantic affinity and boundary
问题1:为什么类别的语义相似度是类别无关的?可以利用语义相似度进行迁移?
方法框架
在WSSS的框架下利用base类别的像素级标注学习从base类别到novel类别的相似度迁移,因此可以获得更高质量的novel类别的CAM
详细过程
在弱监督语义分割的框架下:
- 生成类别激活图(CAM)
- refine生成类别激活图
- 利用pseudo GT训练传统的语义分割网络
其中CAM的缺点在于只关注类别的突出部分,因此会存在部分类别区域像素没有被正确分类,本文的出发点在于基于生成的CAM,向外扩展CAM得到更加精确的CAM
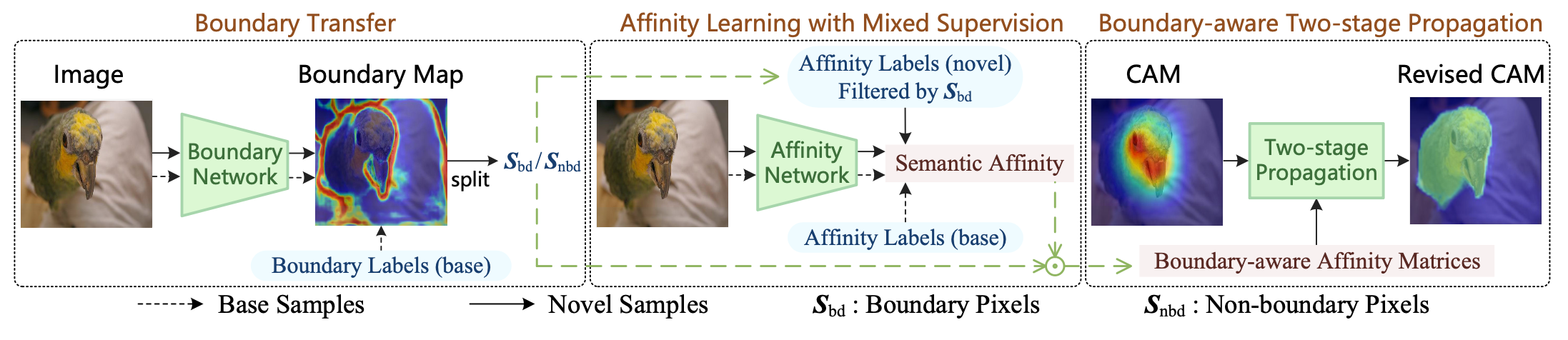
因此在语义相似度和边界是类别无关的前提下,提出一种方法,Response Expansion by Transferring semantic Affinity and Boundary (RETAB),包括了相似度学习步骤和基于相似度的推理步骤:
- 相似度学习步骤:
设计相似度学习网络从base category的逐像素标注gt和novel category生成的CAM学习语义相似度。由于生成CAM在语义边界包含一定的噪声,因此这里根据base category训练一个边界网络,对包含novel category的数据预测边界,边界内是base category,边界外是novel category,在训练相似度网络时,只关注CAM边界外的区域
- 基于相似度的推理步骤:
分为两阶段:
- CAM边界外区域随机游走,根据相似度进行像素膨胀
- CAM边界内区域随机游走,在边界外像素的正则下修正像素预测值
通过两阶段之后得到修正的CAM,即最终的伪标签,最后再根据base category的GT和novel category的伪标签训练一个语义分割网络

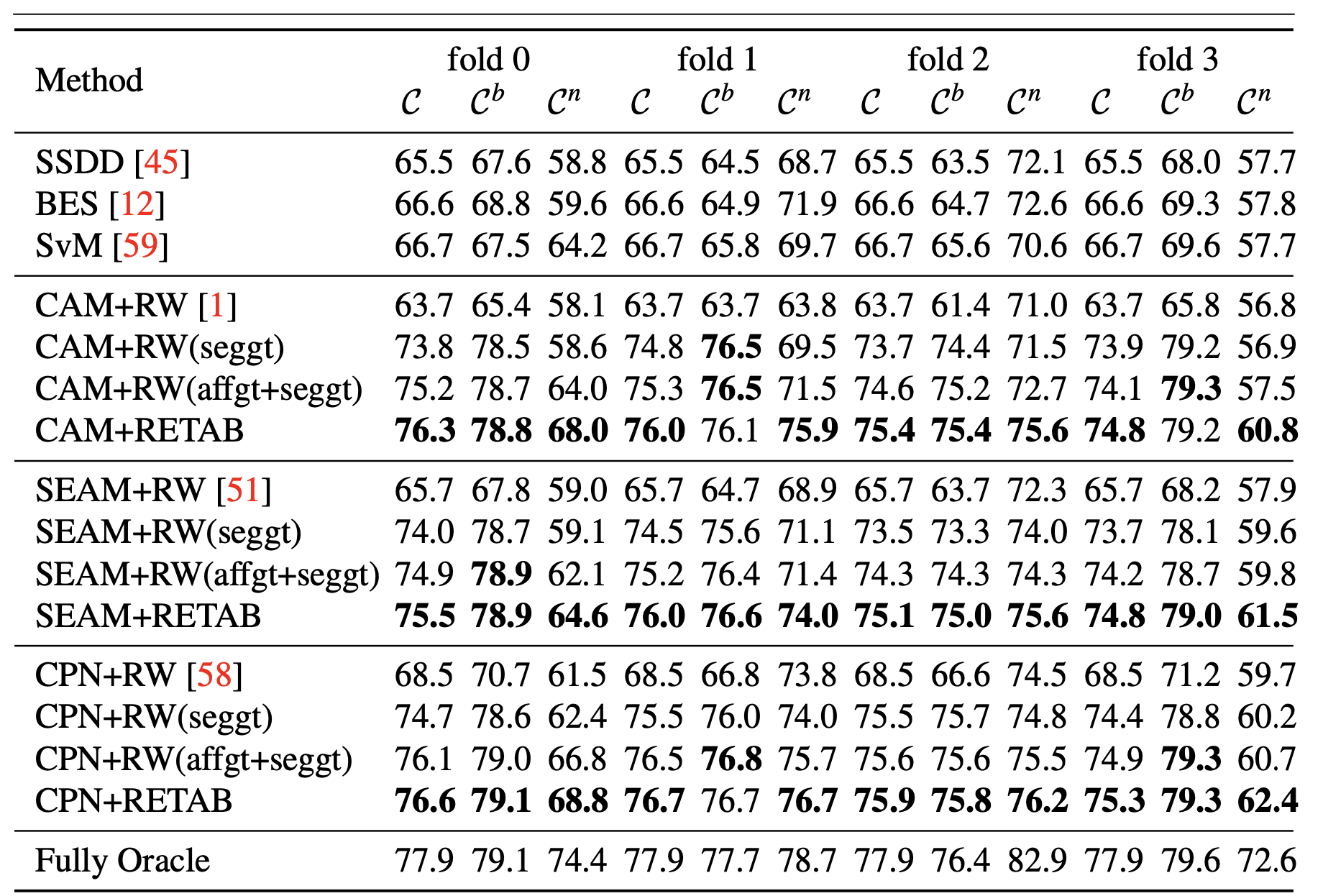
一些细节
base样本只包含base category,但是novel样本可能包含base category或者novel category
关于CAM
论文2 Weak-shot Semantic Segmentation via Dual Similarity Transfer
总结
弱样本学习中的相似度迁移对遥感图像语义分割的借鉴,遥感图像分割数据集的标注往往花费的成本要更多
在主流任务下增加一些限制条件就可以定义一个新的任务
相似度的引入,更多相似度的探索
- Post title:weak-shot-learning
- Post author:calcium_oxide
- Create time:2022-11-19 13:12:09
- Post link:https://yhg1010.github.io/2022/11/19/weak-shot-learning/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.