机器学习
第一章
课程大纲
机器学习:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
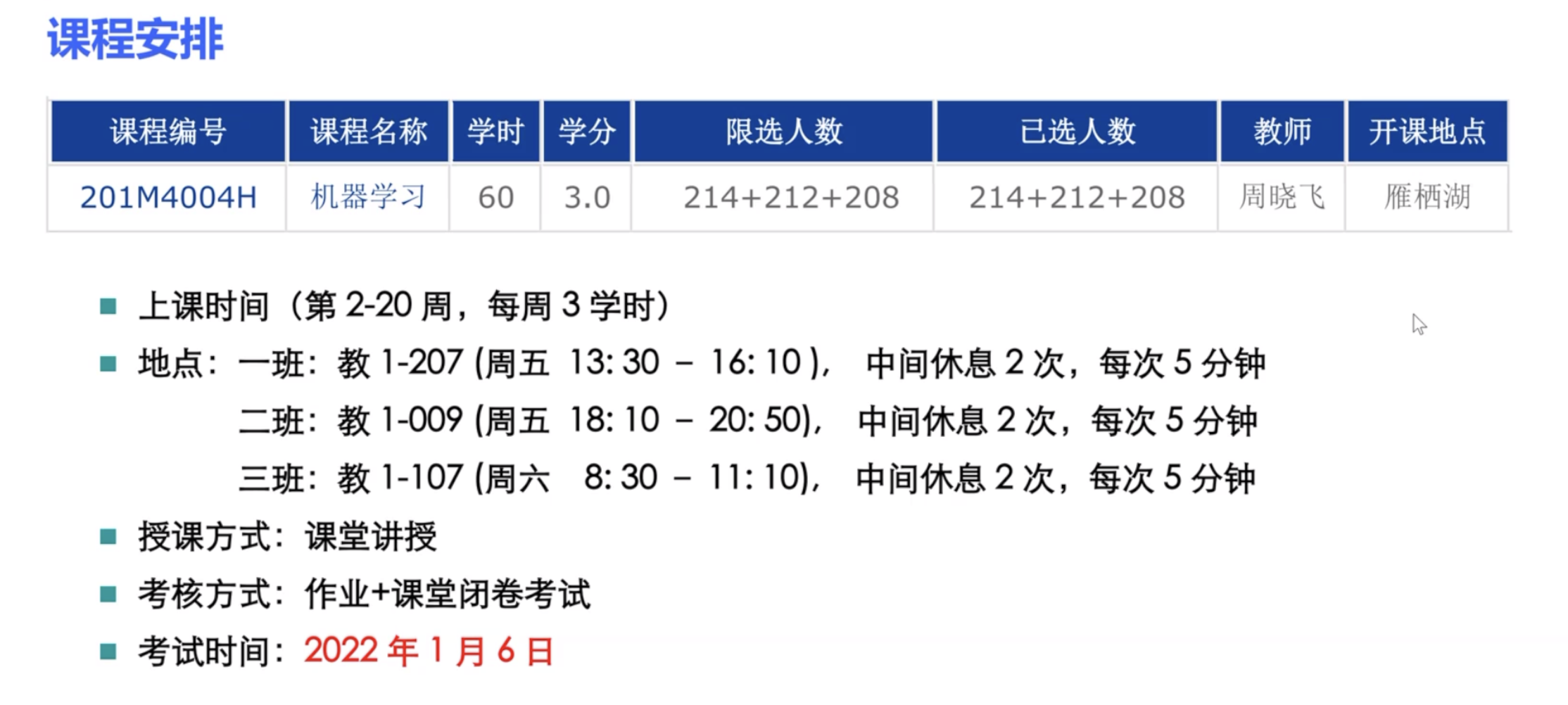
| 第一章 绪论 3学时
第1节 机器学习研究背景
第2节 机器学习研究的问题
第3节 课程主要内容
第4节 课程安排
第二章 贝叶斯方法 6学时
第1节 概述
第2节 贝叶斯决策论
第3节 贝叶斯分类器
第4节 贝叶斯学习与参数估计问题
第三章 线性分类 9学时
第1节 概述
第2节 基础知识
第3节 感知机
第4节 Fisher鉴别
第5节 Logistic回归
第四章 非线性分类 9学时
第1节 概述
第2节 决策树
第3节 集成学习
第4节 最近邻方法
第5节 支持向量机与核函数
第五章 回归分析 3学时
第1节 概述
第2节 最小二乘估计
第3节 最大似然估计
第4节 扩展的非线性模型
第5节 误差分析
第六章 聚类分析 3学时
第1节 概述
第2节 序贯方法
第3节 层次聚类
第4节 K均值聚类
第七章 特征降维 6学时
第1节 概述
第2节 特征选择
第3节 特征降维
第八章 信息论模型 3学时
第1节 概述
第2节 熵、最大熵
第3节 互信息
第4节 信息论优化模型
第九章 概率图模型 6学时
第1节 概述
第2节 有向图模型:贝叶斯网络
第3节 无向图模型:马尔可夫随机场
第4节 学习与推断
第5节 隐马尔可夫模型
第十章 神经网络与深度学习 12学时
第1节 前馈网络
第2节 卷积网络
第3节 Recurrent网络
第4节 神经网络与深度学习前沿概述
|
模式识别与机器学习:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| 第一章 概述 3学时 黄庆明
第1节 课程主要内容和规划
第2节 模式识别的基本概念
第3节 模式识别简史和应用
第4节 模式识别的方法
第5节 模式识别系统
第6节 相关数学基础
第二章 统计判别 3学时 黄庆明
第1节 贝叶斯判别准则
第2节 最小风险判别
第3节 正态分布模式的贝叶斯分类器
第4节 均值向量和协方差矩阵的参数估计
第三章 判别函数 6学时 黄庆明
第1节 线性判别函数
第2节 广义线性判别函数
第3节 分段线性判别函数
第4节 模式空间和权空间
第5节 Fisher线性判别
第6节 感知器算法
第7节 多模式分类
第8节 迭代训练算法
第9节 势函数法
第10节 决策树
第四章 特征选择和提取 3学时 黄庆明
第1节 模式类别可分性
第2节 特征选择
第3节 K-L变换
第五章 统计学习理论基础 3学时 常虹
第1节 机器学习简史和应用
第2节 机器学习任务分类
第3节 参数学习
第4节 过拟合
第5节 偏差方差分析
第6节 正则化方法和泛化理论分析
第六章 监督学习 3学时 常虹
第1节 线性回归模型
第2节 判别式分类模型和逻辑回归
第3节 生成式分类模型和贝叶斯模型
第七章 支持向量机 6学时 常虹
第1节 支持向量机基础理论
第2节 拉格朗日乘子法和对偶问题
第3节 线性支持向量机
第4节 软间隔的支持向量机
第5节 核方法支持向量机
第6节 支持向量回归
第7节 SMO求解方法
第八章 聚类 3学时 郭嘉丰
第1节 无监督学习与有监督学习对比
第2节 距离计算
第3节 聚类算法的评价方法
第4节 经典聚类方法
第九章 降维 3学时
第1节 维度的选择和抽取
第2节 线性降维
第3节 非线性降维和流形模型
第十章 半监督学习 3学时 郭嘉丰
第1节 自我训练
第2节 多视角学习
第3节 生成模型
第4节 S3VMs
第5节 基于图的算法
第6节 半监督聚类
第十一章 概率图模型 3学时 郭嘉丰
第1节 有向概率图模型
第2节 无向概率图模型
第3节 学习和推断
第4节 典型的概率图模型
第十二章 集成学习 3学时 山世光
第1节 机器学习中的哲学思想
第2节 分类器设计中的重采样技术
第3节 模型性能评估
第十三章 深度学习及应用 12学时 山世光
第1节 人工神经网络的生物原型
第2节 生物视觉系统简介
第3节 卷积神经网络CNN源起与概述
第4节 典型卷积神经网络结构
第5节 循环神经网络
第6节 反向传播算法介绍
第7节 深度模型训练技巧
第8节 深度模型应用
第9节 深度学习未来发展趋势
第十四章 课程复习 3学时 常虹
第1节 课程复习
第十五章 期末考试 3学时 郭嘉丰
第1节 期末考试
|
课程安排
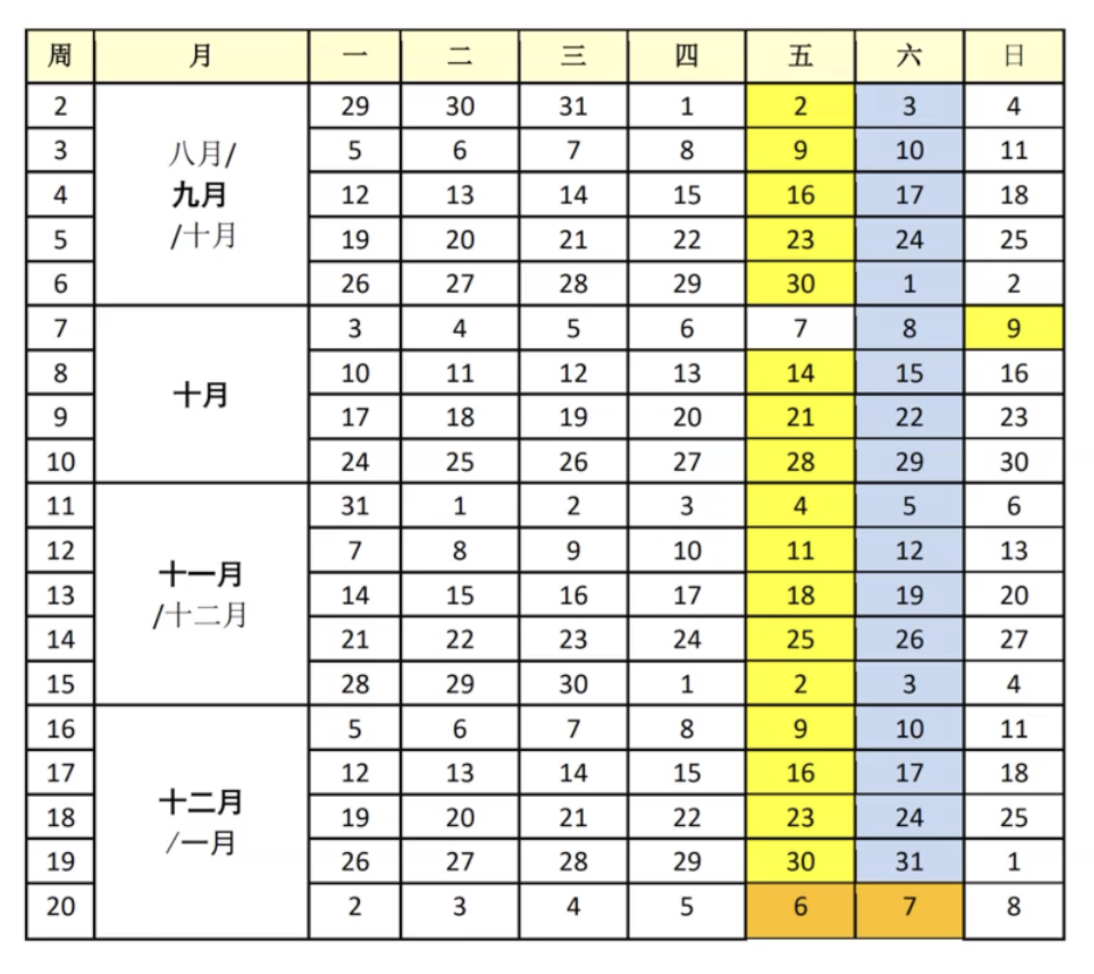
课程时间
第二章 贝叶斯学习

- 似然:关于样本的分布
- 先验:关于类别的分布
- 后验:类别关于样本的分布


MLE和MAP
概率和统计:
- 概率是已知模型和参数的情况下预测结果的方差、均值等情况
- 统计是已知结果预测模型和参数
MLE是最大似然估计,在已知结果的情况下估计参数使得似然函数达到最大
MAP是最大后验概率估计,在MLE的基础上加入了先验概率的『惩罚』
多维正态分布概率密度

贝叶斯学习与参数估计问题
在不同分布下的ML、MAP参数估计
第三章 线性分类
常用的统计量:


模式识别与机器学习
第一章 概述
第二章 贝叶斯学习
第三章 判别函数
线性判别函数
- 多类情况1和多类情况2的比较:
M类进行分类,多类情况1需要M类判别函数,多类情况2需要M(M-1)/2类判别函数
广义线性判别函数
判别函数将每个常数项、一次项、二次项…都作为一个维度,将低维映射到高维
分段线性判别函数
模式空间和权空间
Fisher线性判别
如何根据实际情况找到一条最好的、最易于分类的投影线就是Fisher线性判别方法要解决的基本问题
最重要的是投影线的方向,大小不是很重要
一些参数:
- 样本均值
- 样本类内离散度矩阵和总样本类内离散度矩阵
- 样本类间离散度矩阵
Fisher准则函数:


